How Large Language Models Like ChatGPT Actually Work
DP
If you've been captivated by the capabilities of AI tools like ChatGPT, you've witnessed the power of Large Language Models (LLMs). But what's really going on under the hood? Let's peel back the layers and explore the core technology driving this AI revolution: the Transformer.
The name "GPT" gives us some initial clues
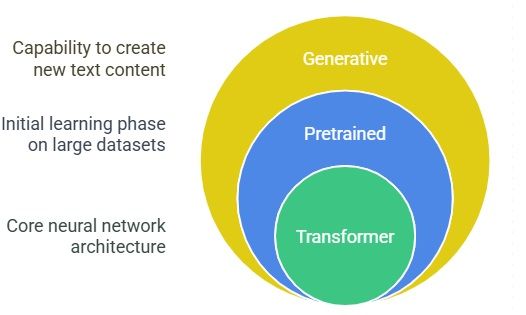
- Generative: These models are built to generate new content, specifically text in this case.
- Pretrained: They have undergone an initial, extensive learning phase on a massive dataset1. This pretraining gives them a broad understanding of language, though they can often be further refined ("fine-tuned") for specific tasks.
- Transformer: This is the truly pivotal piece1. The Transformer is a specific kind of neural network, a machine learning model, and it's the fundamental invention that underpins the current surge in AI capabilities.
The Core Task: Predicting the Next Token
At its heart, a model like ChatGPT is trained to do one thing exceptionally well: given a piece of text, it predicts what comes next in the passage. This prediction isn't just a single word; it's expressed as a probability distribution across potentially many different possible chunks of text that might follow. These chunks are referred to as tokens.
While predicting the next token might seem simple, it's the mechanism used to generate longer, coherent text. Here's how it works in a loop when you interact with the model6...:
- You provide an initial piece of text (your prompt or part of the conversation).
- The model processes this text and predicts the probability distribution for the very next token
- Instead of just picking the single most likely token, the model typically samples from this probability distribution.
- The sampled token is then appended to the original text.
- The entire accumulated text (original plus the new token) is fed back into the model, and the process repeats.
- This cycle of repeated prediction and sampling is precisely what you observe when ChatGPT generates text one word (or token) at a time.
- To make this prediction model behave like a conversational chatbot, an initial piece of text (a "system prompt") sets the stage, defining its role as a helpful AI assistant, and your input becomes the starting point for the dialogue.
- The model then predicts what such an assistant would say next.
- The sources mention that while this seems simple, using larger models like GPT-3 makes this process yield surprisingly sensible results compared to smaller ones like GPT-2.
Jargons
Tokenization: The input text is first broken down into those small pieces called tokens. For text, these are often words, parts of words, or common character sequences. For other data types like images or sound, tokens could be patches or chunks.
Embedding: Each token is then converted into a vector (a list of numbers). This vector is intended to encode the token's meaning. Tokens with similar meanings tend to have vectors located close together in this space.
Attention Blocks: The sequence of vectors passes through an attention block. This is a crucial operation that allows the vectors to interact and share information based on context. For instance, it helps the model understand the different meanings of "model" in "machine learning model" versus "fashion model" by considering surrounding words. The meaning of a word is fully encoded in its vector's entries.
Multi-Layer Perception (Feed-Forward) Blocks: After attention, vectors pass through another operation, sometimes called a multi-layer perception or feed-forward layer. In this step, vectors are processed independently and in parallel. This step is described as being similar to asking many questions about each vector and updating it based on the answers.
Repetition: The attention and multi-layer perceptron steps are repeated multiple times.
Final Vector: The goal is that by the end of these repeated transformations, the very last vector in the sequence has absorbed the essential meaning and context of the entire input passage.
Prediction: An operation is performed on this final vector to produce the raw values that will determine the probability distribution over all possible next tokens.